
Às vezes eu me pergunto se as pessoas da minha área têm noção de quão sortudos nós somos. Os físicos adorariam viajar no tempo para conversar com o Newton, os matemáticos adorariam conversar com o Euclides, os biólogos adorariam conversar com o Darwin. Mas nós podemos conversar com o Knuth!

Nós temos a sorte de viver no mesmo período de tempo que o criador da análise de algoritmos, que é uma das bases da Ciência da Computação. Se você gosta do assunto, vale a pena juntar uns trocos e viajar até a Califórnia para assistir a uma das palestras dele (dica: todo fim de ano, inspirado nas árvores de Natal, ele faz uma palestra de estrutura de dados, falando sobre árvores; elas também estão online se você não tiver como ver ao vivo).
Eu fiz a peregrinação em 2011, quando consegui assistir a uma das palestras dele. Aproveitei para ir todo contente pegar minha recompensa por ter achado um erro no Art of Computer Programming, mas ele, marotamente, me disse que aquilo que eu achei não era um erro, era uma pegadinha, e eu caí! (Mas eu não vou falar qual a pegadinha, vá na página 492 do TAOCP volume 4A, primeira edição, e confira você mesmo :)

Nesse dia perguntaram que opinião ele tinha sobre o problema mais difícil da nossa geração, P=NP. A intuição dele é que provalmente é verdade, mas ele acredita que se acharmos a demonstração, ela vai ser não-construtiva. O que isso significa? O que é uma demonstração não-construtiva?
Em análise de algoritmos, as demonstrações construtivas são as mais comuns. Por exemplo, digamos que eu quero provar que é possível calcular x elevado a y em tempo O(y). Isso é fácil, basta construir um algoritmo assim:
E se eu quiser provar que esse mesmo problema pode ser resolvido em tempo O(log y)? Novamente, tudo que eu preciso fazer é exibir um algoritmo que implemente isso:
(Nesse caso eu também precisaria provar que esse algoritmo é de fato O(log y), já não é óbvio por inspeção). Nos dois casos temos exemplos de demonstrações construtivas: se eu quero provar uma propriedade P, basta exibir um algoritmo que tenha essa propriedade P.
As demonstrações não-construtivas são diferentes. Nelas, eu posso provar a propriedade P sem mostrar o algoritmo, através de alguma propriedade matemática do modelo.
Por exemplo, imagine que eu tenho uma lista ordenada de números. Se eu fizer uma busca binária, posso achar a posição de um número dado com O(log n) comparações. Mas é possível criar um algoritmo mais rápido que isso? Eu digo que não é possível, e para isso vou fazer uma prova não-construtiva de que esse é o mínimo que um algoritmo de busca precisa para funcionar.
Para isso eu vou usar a teoria da informação de Shannon. Essa teoria é surpreendentemente intuitiva, e se baseia no conceito de surpresa. Se eu te falar que o céu ficou escuro às 19h, você não vai achar nada de mais, nessa hora o Sol está se pondo, então é natural que o céu fique escuro. Mas e se eu falar que o céu ficou escuro às 10 da manhã? Foi uma tempestade? Um eclipse? A nave do Independence Day?
Intuitivamente, quanto mais surpresos nós ficamos com uma sentença, mais informação ela tem. O Shannon definiu então a quantidade de informação como sendo uma função monotônica da probabilidade do evento acontecer:

Se o evento é raro, tem bastante informação; se o evento é comum, tem pouca informação. A base do logaritmo fornece a unidade de medida, se a base for 2, então a informação é medida em bits.
E quanta informação nós ganhamos com uma comparação? Se a chance de dar verdadeiro ou falso for a mesma, então a chance é p(m)=1/2, logo a informação é I(m)=1. Você ganha exatamente um bit de informação com uma comparação.
Qual o resultado do nosso algoritmo de busca? O resultado é um índice, se nós temos n elementos no vetor, então a resposta é um índice que varia de 0 a n-1. Logo, a probabilidade de você escolher o índice certo ao acaso é p(m)=1/n, já que a escolha é uniforme.
Quanta informação tem essa escolha, então? Fazendo a conta:

Se você precisa de log n bits para descrever a resposta, e você ganha só 1 bit por comparação, então não tem como um algoritmo rodar em menos que O(log n): a informação tem que vir de algum lugar! Com isso, nós mostramos que qualquer algoritmo precisa rodar no mínimo em tempo O(log n), e sem precisar mostrar o algoritmo em si. Essa é uma demonstração não-construtiva.
Pressinto a pergunta: "mas RicBit, e a busca com hash table, ela não é O(1)?". Sim, ela é! Mas ela não usa comparações, e a nossa análise foi exclusivamente para métodos baseados em comparações. Com um acesso a uma hash você pode ganhar mais que 1 bit de informação por operação.
Um outro exemplo é achar o limite dos algoritmos de ordenação. Suponha que eu tenho um vetor com elementos bagunçados e quero ordená-los usando comparações. Eu sei que cada comparação ganha 1 bit de informação, então só preciso saber quanta informação tem na saída.
Qual o resultado do algoritmo? Um vetor ordenado. Mas os valores do vetor em si são irrelevantes, o que importa mesmo é saber a ordem relativa entre eles. Essa ordem relativa pode ser expressa como uma permutação dos itens originais.
Quantas permutações existem? Se o vetor tem tamanho n, então existem n! permutações, logo a probabilidade é 1/n!. Fazendo as contas:

Primeiro você usa a aproximação de Stirling, depois joga fora todos os termos assintoticamentes menores que o dominante. O resultado é que nós provamos que nenhuma ordenação pode ser melhor que O(n log n), sem precisar mostrar nenhum algoritmo!
Novamente, esse resultado só vale para ordenações baseadas em comparações. Sem usar comparações, você tem métodos como radix sort e ábaco sort que são melhores que O(n log n).
Esse método de análise da quantidade de informação pode ser utilizado em qualquer algoritmo, desde que você note um detalhe muito importante: o método acha um limite inferior para a complexidade, mas não prova que esse algoritmo existe! Tudo que conseguimos provar como ele é que, se o algoritmo existir, então ele não pode ser melhor que o limite achado.

Nós temos a sorte de viver no mesmo período de tempo que o criador da análise de algoritmos, que é uma das bases da Ciência da Computação. Se você gosta do assunto, vale a pena juntar uns trocos e viajar até a Califórnia para assistir a uma das palestras dele (dica: todo fim de ano, inspirado nas árvores de Natal, ele faz uma palestra de estrutura de dados, falando sobre árvores; elas também estão online se você não tiver como ver ao vivo).
Eu fiz a peregrinação em 2011, quando consegui assistir a uma das palestras dele. Aproveitei para ir todo contente pegar minha recompensa por ter achado um erro no Art of Computer Programming, mas ele, marotamente, me disse que aquilo que eu achei não era um erro, era uma pegadinha, e eu caí! (Mas eu não vou falar qual a pegadinha, vá na página 492 do TAOCP volume 4A, primeira edição, e confira você mesmo :)

Eu e Knuth, o trollzinho
Nesse dia perguntaram que opinião ele tinha sobre o problema mais difícil da nossa geração, P=NP. A intuição dele é que provalmente é verdade, mas ele acredita que se acharmos a demonstração, ela vai ser não-construtiva. O que isso significa? O que é uma demonstração não-construtiva?
Demonstrações construtivas e não-construtivas
Em análise de algoritmos, as demonstrações construtivas são as mais comuns. Por exemplo, digamos que eu quero provar que é possível calcular x elevado a y em tempo O(y). Isso é fácil, basta construir um algoritmo assim:
E se eu quiser provar que esse mesmo problema pode ser resolvido em tempo O(log y)? Novamente, tudo que eu preciso fazer é exibir um algoritmo que implemente isso:
(Nesse caso eu também precisaria provar que esse algoritmo é de fato O(log y), já não é óbvio por inspeção). Nos dois casos temos exemplos de demonstrações construtivas: se eu quero provar uma propriedade P, basta exibir um algoritmo que tenha essa propriedade P.
As demonstrações não-construtivas são diferentes. Nelas, eu posso provar a propriedade P sem mostrar o algoritmo, através de alguma propriedade matemática do modelo.
Por exemplo, imagine que eu tenho uma lista ordenada de números. Se eu fizer uma busca binária, posso achar a posição de um número dado com O(log n) comparações. Mas é possível criar um algoritmo mais rápido que isso? Eu digo que não é possível, e para isso vou fazer uma prova não-construtiva de que esse é o mínimo que um algoritmo de busca precisa para funcionar.
A Teoria de Shannon aplicada à busca binária
Para isso eu vou usar a teoria da informação de Shannon. Essa teoria é surpreendentemente intuitiva, e se baseia no conceito de surpresa. Se eu te falar que o céu ficou escuro às 19h, você não vai achar nada de mais, nessa hora o Sol está se pondo, então é natural que o céu fique escuro. Mas e se eu falar que o céu ficou escuro às 10 da manhã? Foi uma tempestade? Um eclipse? A nave do Independence Day?
Intuitivamente, quanto mais surpresos nós ficamos com uma sentença, mais informação ela tem. O Shannon definiu então a quantidade de informação como sendo uma função monotônica da probabilidade do evento acontecer:
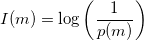
Se o evento é raro, tem bastante informação; se o evento é comum, tem pouca informação. A base do logaritmo fornece a unidade de medida, se a base for 2, então a informação é medida em bits.
E quanta informação nós ganhamos com uma comparação? Se a chance de dar verdadeiro ou falso for a mesma, então a chance é p(m)=1/2, logo a informação é I(m)=1. Você ganha exatamente um bit de informação com uma comparação.
Qual o resultado do nosso algoritmo de busca? O resultado é um índice, se nós temos n elementos no vetor, então a resposta é um índice que varia de 0 a n-1. Logo, a probabilidade de você escolher o índice certo ao acaso é p(m)=1/n, já que a escolha é uniforme.
Quanta informação tem essa escolha, então? Fazendo a conta:
Se você precisa de log n bits para descrever a resposta, e você ganha só 1 bit por comparação, então não tem como um algoritmo rodar em menos que O(log n): a informação tem que vir de algum lugar! Com isso, nós mostramos que qualquer algoritmo precisa rodar no mínimo em tempo O(log n), e sem precisar mostrar o algoritmo em si. Essa é uma demonstração não-construtiva.
Pressinto a pergunta: "mas RicBit, e a busca com hash table, ela não é O(1)?". Sim, ela é! Mas ela não usa comparações, e a nossa análise foi exclusivamente para métodos baseados em comparações. Com um acesso a uma hash você pode ganhar mais que 1 bit de informação por operação.
O limite da ordenação
Um outro exemplo é achar o limite dos algoritmos de ordenação. Suponha que eu tenho um vetor com elementos bagunçados e quero ordená-los usando comparações. Eu sei que cada comparação ganha 1 bit de informação, então só preciso saber quanta informação tem na saída.
Qual o resultado do algoritmo? Um vetor ordenado. Mas os valores do vetor em si são irrelevantes, o que importa mesmo é saber a ordem relativa entre eles. Essa ordem relativa pode ser expressa como uma permutação dos itens originais.
Quantas permutações existem? Se o vetor tem tamanho n, então existem n! permutações, logo a probabilidade é 1/n!. Fazendo as contas:
Primeiro você usa a aproximação de Stirling, depois joga fora todos os termos assintoticamentes menores que o dominante. O resultado é que nós provamos que nenhuma ordenação pode ser melhor que O(n log n), sem precisar mostrar nenhum algoritmo!
Novamente, esse resultado só vale para ordenações baseadas em comparações. Sem usar comparações, você tem métodos como radix sort e ábaco sort que são melhores que O(n log n).
A análise por quantidade de informação
Esse método de análise da quantidade de informação pode ser utilizado em qualquer algoritmo, desde que você note um detalhe muito importante: o método acha um limite inferior para a complexidade, mas não prova que esse algoritmo existe! Tudo que conseguimos provar como ele é que, se o algoritmo existir, então ele não pode ser melhor que o limite achado.
Nenhum comentário:
Postar um comentário