
Era uma vez, há mais de cem anos atrás, uma família de matemáticos. O avô era matemático, o pai era matemático, e o filho mudou de cidade para estudar matemática na melhor universidade do país. O pai lhe deu algum dinheiro para pagar o aluguel enquanto estivesse estudando, mas ele não contava com os preços altos. Naquela cidade, o dinheiro que ele tinha não era suficiente para alugar um quartinho.
O filho então precisava mandar uma mensagem para o pai, pedindo mais dinheiro. Naquela época, o meio de comunicação mais rápido era o telégrafo, mas você pagava por cada letra enviada. Por isso, a mensagem tinha que ser bastante sucinta. Depois de pensar um pouco, mandou para o pai a mensagem "SEND+MORE=MONEY".
Ao receber a mensagem, primeiro o pai ficou perplexo. Quanto dinheiro ele precisava mandar? Depois de pensar um pouco, ele logo concluiu: "Ah, eu preciso mandar $10652 para ele!".
Como o matemático pai chegou a essa conclusão?

Esse problema é um exemplo de Criptoaritmética. A solução é trocar as letras por números, de tal maneira que a cada letra corresponda um único número, e de modo que a adição resultante seja verdadeira. No caso descrito acima, só existe uma solução válida, que é M=1, Y=2, E=5, N=6, D=7, R=8, S=9 e O=0.


Você pode achar essa solução usando apenas deduções lógicas. Por exemplo, M precisa ser 1 porque o carry (vai-um) da primeira coluna nunca pode ser maior que um. Com raciocínios similares você descobre os números restantes.
Resolver problemas assim é bastante divertido! Meu primeiro contato com Criptoaritmética foi na revista Micro Sistemas #46, de julho de 85, onde eles apresentam um gerador de criptogramas, para que você possa resolvê-los na mão. Na época eu era viciado, gostava tanto que até cheguei a portar esse gerador para Pascal já na época dos PCs.
Já na revista MSX Micro #15, de maio de 88, um desafio mais difícil foi proposto pelo Nabor Rosenthal: escrever um programa de computador que resolva sozinho os criptogramas!
Como fazer um programa assim? Existem três abordagens imediatas. A primeira é usar força bruta para enumerar todas as combinações entre letras e números. Cada uma das 8 letras pode assumir 10 valores distintos, então o tamanho do espaço de estados é 8**10 = 1073741824 combinações.
A segunda abordagem é notar que duas letras não podem ter o mesmo número, então você não precisa visitar todos os estados, só aqueles que contém permutações dos oito dígitos escolhidos. Assim, o espaço fica apenas com binomial(10, 8)*fatorial(8) = 1814400 combinações, quase mil vezes menor que o anterior.
A terceira é usar backtracking para eliminar da árvore de busca as combinações inválidas. Por exemplo, se você já determinou que D=7 e E=5, então Y precisa necessariamente ser 2 porque é a única possibilidade que faz a última coluna ficar correta. Essa opção é mais complicada de implementar, mas é ainda mais rápida que a anterior.
Nesse ano eu fiz um curso de Discrete Optimization no Coursera, e aprendi um método novo para resolver criptogramas. Porém, antes de explicar esse método novo, vale a pena fazer uma pausa para estudar um problema mais simples.
Enquanto o dinheiro do pai não chegava, o estudante estava dormindo de hóspede numa fazenda da região. Embora ele não pagasse nada para dormir no celeiro, ele ainda tinha que comprar comida. E só tinham três comidas disponíveis para comprar: espigas de milho, pães e copos de leite. Dado que ele precisa de pelo menos 2000 calorias por dia, e 5000 unidades de vitamina A, qual é o menor custo diário que ele pode ter para conseguir todos os nutrientes que precisa?
.jpg)
Esse problema pode ser expresso através de uma série de inequações:

Na literatura, problemas com esse formato são estudados em Programação Linear, e existem vários algoritmos eficientes para resolvê-los, como os métodos de Ponto Interior, que podem ser implementados de forma a garantir uma solução em tempo polinomial. Na prática, usa-se mais o Simplex, que tem um pior caso ruim, mas também é polinomial no caso médio.
Usando essas técnicas para resolver o problema, temos que a melhor solução é comprar 17.13 espigas e 6.33 copos de leite, gastando um total de $2.82.
Mas agora tem um problema: eles não vendem 17.13 espigas, a quantidade precisa ser um inteiro. Ou você compra 17 espigas, ou compra 18. Fácil de resolver, é só arredondar para cima né? Leva-se 18 espigas e 7 copos de leite, gastando $3.05, e garantindo todos os nutrientes que você precisa.
Porém, se você fizer isso, você vai perder dinheiro! Pode conferir: se você comprar 10 espigas, 8 copos de leite, e 5 pães, vai gastar só $2.89, e continuar garantindo o mínimo de nutrientes diários. Os métodos de programação linear não funcionam quando os valores precisam ser inteiros!
Uma maneira de chegar a esse resultado é quebrando o problema em dois. Se a sua solução tem um valor fracionário, como 17.13, então você roda o Simplex mais duas vezes: na primeira adicionando a inequação M≤17, e na segunda, M≥18. Se o resultado tiver só variáveis inteiras, beleza, está resolvido. Senão, você pega a variável fracionária e quebra em dois de novo. Esse método na literatura é a Programaçao Inteira Mista (ou apenas MIP).

Opa! Peraí! Os métodos de programação linear eram polinomiais, e abrindo uma árvore em cada variável nós transformamos o método em exponencial. É uma perda de performance inaceitável!
Pois é, mas não tem jeito. Embora a programação linear seja polinomial, a programação inteira é NP-hard. Se você achar um método polinomial para resolver esse problema, então você também provou que P=NP.
Nem tudo está perdido, entretanto. Existem vários métodos para otimizar a busca, de modo que você não precise visitar todos os nós da árvore. Por exemplo, você pode usar branch and bound, branch and cut, Gomory cuts, e mais inúmeros truques que deixam o número de nós baixos o suficiente para o método ser viável na prática.
Implementar esses métodos pode ser bem difícil. A boa notícia é que você não precisa fazê-lo! Existem inúmeras bibliotecas prontas que implementam tudo isso para você, em quase todas as linguagens do mercado. A minha preferida é a SCIP, que é open source e bastante competitiva com as soluções comerciais. O único problema dela é que o público-alvo são os pesquisadores da área, então a API é bem complexa e intimidadora para quem está começando agora. Se você quer começar agora a brincar com MIP, eu tenho uma alternativa melhor.
Já que a SCIP é boa, mas é difícil de usar, meu primeiro instinto foi escrever uma abstração sobre ela que torne a programação mais simples. E assim surgiu o EasySCIP, um binding em C++ que é fácil de usar. Para mostrar como é simples, vamos implementar o problema da dieta em EasySCIP.
Primeiro você cria uma instância do EasySCIP:
Depois, cria as variáveis, uma para cada tipo de alimento. Na criação da variável, você especifica os limites onde ela pode variar (digamos, de 0 a 1000). Além disso, você passa o coeficiente dessa variável na função que vai ser minimizada (no nosso caso, é o preço de cada item):
Agora você adiciona as inequações (constraints). Para cada inequação, você passa o coeficiente da variável, e os limites inferiores e superiores. No nosso caso, só nos importam os limites inferiores, então eu chutei um valor alto para o superior. A primeira inequação fica assim:
Na segunda inequação você nem precisa adicionar a variável do pão, porque ele não tem nenhuma vitamina A.
Agora é só resolver e ler os valores finais:
O programa completo você pode ver no github. Rodando o programa, ele retorna a solução que esperávamos:
Repetindo uma equação dessas para cada letra, nós garantimos que a cada letra corresponde um dígito. Mas isso não é suficiente, você também precisa garantir o oposto: a cada dígito precisa corresponder uma letra. Sem essa condição adicional, você poderia ter uma solução do tipo S=9 e E=9 (mas não podemos ter o mesmo dígito em duas letras distintas).
A solução é parecida com a anterior. Para o dígito 9, por exemplo, teremos:

Note que temos apenas oito letras distintas para dez dígitos, então pelo menos dois dígitos vão sobrar. Como não temos como garantir qual dígito será utilizado, usamos uma inequação ao invés de uma equação.
Outra regra que precisa ser modelada é que nenhum número pode começar com zero. Isso é o mesmo que dizer que as letras S e M não podem ser zero. Mais duas equações resolvem isso:

Agora falta só modelar a soma em si. Antes de começar, vale notar que o problema tem quatro variáveis binárias escondidas que você precisa levar em conta: os carrys de cada coluna.

Agora basta escrever uma equação por coluna. Para a coluna mais à direita, por exemplo, teríamos algo do tipo D+E=Y+10c0 em decimal. Usando as nossas variáveis binárias, a equação completa fica:

Parece assustador, mas é só uma equação linear simples. Fazendo mais uma dessas para cada coluna do nosso puzzle, o modelo está quase completo: falta só uma função objetivo. Se vamos usar MIP, precisamos minimizar alguma coisa. Mas o que minimizar? Nosso modelo já está completo sem a necessidade de minimizar nada, então podemos fornecer uma função constante para ele minimizar. Na linguagem da área, nós estamos buscando feasibility, e não optimality.
Com todas as inequações prontas, podemos rodar o modelo no EasySCIP. O código completo está no github, e, após rodá-lo em meu computador, tive a resposta em 0.116s, o que é bastante respeitável! Mas ainda dá para melhorar :)
Eu sei que gostar de resolver criptoaritmética parece coisa da maluco, mas eu não sou o único maluco nesse mundo, tem o Knuth também! No volume 4A do Art of Computer Programming, ele dá uma dica muito boa para resolver criptogramas: a análise das assinaturas. Vamos isolar a letra E no puzzle original, trocando os lugares onde ela aparece por 1, e onde não aparece por 0:

Após a substituição, nós obtemos a assinatura da letra E, que vale 100+1-10, ou seja, 91. A sacada do Knuth é que, na solução final, a soma das assinaturas precisa necessariamente valer zero:

Usando variáveis inteiras ao invés de variáveis binárias, poderíamos colocar essa equação diretamente no modelo, e aí não precisaríamos das equações de cada coluna! Mas podemos fazer ainda melhor: o MIP sempre quer uma função para minimizar, então podemos mandar ele minimizar a soma das assinaturas. Assim, os métodos de branch and bound implementados pelo SCIP podem jogar fora mais nós da árvore durante o processamento, o que acelera a busca.
O único problema é ele resolver minimizar tanto a soma das assinaturas, que ela acabe ficando negativa. Para evitar isso, é só adicionar essa restrição manualmente. Por exemplo, ele pode minimizar a variável X, onde X satisfaz:

Ainda precisamos adicionar as regras de que a cada letra corresponde um único dígito e vice-versa. Vamos manter as variáveis binárias do modelo anterior, e ensinar o modelo a converter entre variáveis binárias e variáveis inteiras. Por exemplo, a letra D ficaria:

Com isso o modelo está completo. O código está no github, e rodando no EasySCIP, ele chega no mesmo resultado que o modelo anterior, porém usando apenas 0.052s, quase metade do tempo!
Quando eu devo usar MIP ao invés de outros métodos, como backtracking? O backtracking vai criar uma divisão na árvore de busca cada vez que definir o valor de uma variável, mas o MIP roda uma iteração de programação linear em cada nó, o que potencialmente pode definir várias variáveis ao mesmo tempo. A minha experiência é que o MIP ganha sempre que você conseguir criar um modelo que permita essa otimização global.
Como comparação, lembre que a força bruta examinava 1073741824 nós, e a análise de permutações visitava 1814400 nós. Olhando no log do EasySCIP, eu vejo que o primeiro modelo com variáveis binárias visitou apenas 9 nós, e o segundo modelo com assinaturas resolveu tudo em um único nó! A programação linear achou a solução inteira sem nenhum branch! Pelos números, é bem claro que vale a pena aprender a escrever modelos MIP :)
O filho então precisava mandar uma mensagem para o pai, pedindo mais dinheiro. Naquela época, o meio de comunicação mais rápido era o telégrafo, mas você pagava por cada letra enviada. Por isso, a mensagem tinha que ser bastante sucinta. Depois de pensar um pouco, mandou para o pai a mensagem "SEND+MORE=MONEY".
Ao receber a mensagem, primeiro o pai ficou perplexo. Quanto dinheiro ele precisava mandar? Depois de pensar um pouco, ele logo concluiu: "Ah, eu preciso mandar $10652 para ele!".
Como o matemático pai chegou a essa conclusão?

Esse problema é um exemplo de Criptoaritmética. A solução é trocar as letras por números, de tal maneira que a cada letra corresponda um único número, e de modo que a adição resultante seja verdadeira. No caso descrito acima, só existe uma solução válida, que é M=1, Y=2, E=5, N=6, D=7, R=8, S=9 e O=0.
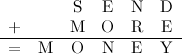
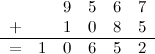
Você pode achar essa solução usando apenas deduções lógicas. Por exemplo, M precisa ser 1 porque o carry (vai-um) da primeira coluna nunca pode ser maior que um. Com raciocínios similares você descobre os números restantes.
Resolver problemas assim é bastante divertido! Meu primeiro contato com Criptoaritmética foi na revista Micro Sistemas #46, de julho de 85, onde eles apresentam um gerador de criptogramas, para que você possa resolvê-los na mão. Na época eu era viciado, gostava tanto que até cheguei a portar esse gerador para Pascal já na época dos PCs.
Já na revista MSX Micro #15, de maio de 88, um desafio mais difícil foi proposto pelo Nabor Rosenthal: escrever um programa de computador que resolva sozinho os criptogramas!
Como fazer um programa assim? Existem três abordagens imediatas. A primeira é usar força bruta para enumerar todas as combinações entre letras e números. Cada uma das 8 letras pode assumir 10 valores distintos, então o tamanho do espaço de estados é 8**10 = 1073741824 combinações.
A segunda abordagem é notar que duas letras não podem ter o mesmo número, então você não precisa visitar todos os estados, só aqueles que contém permutações dos oito dígitos escolhidos. Assim, o espaço fica apenas com binomial(10, 8)*fatorial(8) = 1814400 combinações, quase mil vezes menor que o anterior.
A terceira é usar backtracking para eliminar da árvore de busca as combinações inválidas. Por exemplo, se você já determinou que D=7 e E=5, então Y precisa necessariamente ser 2 porque é a única possibilidade que faz a última coluna ficar correta. Essa opção é mais complicada de implementar, mas é ainda mais rápida que a anterior.
Nesse ano eu fiz um curso de Discrete Optimization no Coursera, e aprendi um método novo para resolver criptogramas. Porém, antes de explicar esse método novo, vale a pena fazer uma pausa para estudar um problema mais simples.
O problema da dieta
Enquanto o dinheiro do pai não chegava, o estudante estava dormindo de hóspede numa fazenda da região. Embora ele não pagasse nada para dormir no celeiro, ele ainda tinha que comprar comida. E só tinham três comidas disponíveis para comprar: espigas de milho, pães e copos de leite. Dado que ele precisa de pelo menos 2000 calorias por dia, e 5000 unidades de vitamina A, qual é o menor custo diário que ele pode ter para conseguir todos os nutrientes que precisa?
.jpg)
| Porção | Calorias (kcal) | Vitamina A (IU) | Preço |
| Espiga de milho | 72 | 107 | $ 0.08 |
| Copo de leite | 121 | 500 | $ 0.23 |
| Pão | 65 | 0 | $ 0.05 |
Esse problema pode ser expresso através de uma série de inequações:
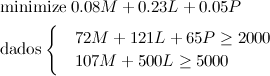
Na literatura, problemas com esse formato são estudados em Programação Linear, e existem vários algoritmos eficientes para resolvê-los, como os métodos de Ponto Interior, que podem ser implementados de forma a garantir uma solução em tempo polinomial. Na prática, usa-se mais o Simplex, que tem um pior caso ruim, mas também é polinomial no caso médio.
Usando essas técnicas para resolver o problema, temos que a melhor solução é comprar 17.13 espigas e 6.33 copos de leite, gastando um total de $2.82.
Mas agora tem um problema: eles não vendem 17.13 espigas, a quantidade precisa ser um inteiro. Ou você compra 17 espigas, ou compra 18. Fácil de resolver, é só arredondar para cima né? Leva-se 18 espigas e 7 copos de leite, gastando $3.05, e garantindo todos os nutrientes que você precisa.
Porém, se você fizer isso, você vai perder dinheiro! Pode conferir: se você comprar 10 espigas, 8 copos de leite, e 5 pães, vai gastar só $2.89, e continuar garantindo o mínimo de nutrientes diários. Os métodos de programação linear não funcionam quando os valores precisam ser inteiros!
Uma maneira de chegar a esse resultado é quebrando o problema em dois. Se a sua solução tem um valor fracionário, como 17.13, então você roda o Simplex mais duas vezes: na primeira adicionando a inequação M≤17, e na segunda, M≥18. Se o resultado tiver só variáveis inteiras, beleza, está resolvido. Senão, você pega a variável fracionária e quebra em dois de novo. Esse método na literatura é a Programaçao Inteira Mista (ou apenas MIP).

Opa! Peraí! Os métodos de programação linear eram polinomiais, e abrindo uma árvore em cada variável nós transformamos o método em exponencial. É uma perda de performance inaceitável!
Pois é, mas não tem jeito. Embora a programação linear seja polinomial, a programação inteira é NP-hard. Se você achar um método polinomial para resolver esse problema, então você também provou que P=NP.
Nem tudo está perdido, entretanto. Existem vários métodos para otimizar a busca, de modo que você não precise visitar todos os nós da árvore. Por exemplo, você pode usar branch and bound, branch and cut, Gomory cuts, e mais inúmeros truques que deixam o número de nós baixos o suficiente para o método ser viável na prática.
Implementar esses métodos pode ser bem difícil. A boa notícia é que você não precisa fazê-lo! Existem inúmeras bibliotecas prontas que implementam tudo isso para você, em quase todas as linguagens do mercado. A minha preferida é a SCIP, que é open source e bastante competitiva com as soluções comerciais. O único problema dela é que o público-alvo são os pesquisadores da área, então a API é bem complexa e intimidadora para quem está começando agora. Se você quer começar agora a brincar com MIP, eu tenho uma alternativa melhor.
Usando EasySCIP
Já que a SCIP é boa, mas é difícil de usar, meu primeiro instinto foi escrever uma abstração sobre ela que torne a programação mais simples. E assim surgiu o EasySCIP, um binding em C++ que é fácil de usar. Para mostrar como é simples, vamos implementar o problema da dieta em EasySCIP.
Primeiro você cria uma instância do EasySCIP:
MIPSolver solver;
Depois, cria as variáveis, uma para cada tipo de alimento. Na criação da variável, você especifica os limites onde ela pode variar (digamos, de 0 a 1000). Além disso, você passa o coeficiente dessa variável na função que vai ser minimizada (no nosso caso, é o preço de cada item):
Variable corn = solver.integer_variable(0, 1000, 0.08); Variable milk = solver.integer_variable(0, 1000, 0.23); Variable bread = solver.integer_variable(0, 1000, 0.05);
Agora você adiciona as inequações (constraints). Para cada inequação, você passa o coeficiente da variável, e os limites inferiores e superiores. No nosso caso, só nos importam os limites inferiores, então eu chutei um valor alto para o superior. A primeira inequação fica assim:
Constraint calories = solver.constraint(); calories.add_variable(corn, 72); calories.add_variable(milk, 121); calories.add_variable(bread, 65); calories.commit(2000, 200000);
Na segunda inequação você nem precisa adicionar a variável do pão, porque ele não tem nenhuma vitamina A.
Constraint vitamin_a = solver.constraint(); vitamin_a.add_variable(corn, 107); vitamin_a.add_variable(milk, 500); vitamin_a.commit(5000, 500000);
Agora é só resolver e ler os valores finais:
Solution sol = solver.solve(); cout << "Corn: " << sol.value(corn) << "\n"; cout << "Milk: " << sol.value(milk) << "\n"; cout << "Bread: " << sol.value(bread) << "\n";
O programa completo você pode ver no github. Rodando o programa, ele retorna a solução que esperávamos:
Corn: 10 Milk: 8 Bread: 5
Agora já temos as ferramentas que precisávamos para resolver o problema original!
MIP é uma ferramenta excelente para resolver puzzles. Tudo que você precisa fazer é arrumar uma maneira de transformar seu puzzle em um sistema de inequações; feito isso, o framework faz todo o serviço sujo para você.
O problema então deixa de ser programação e passa a ser modelagem. Qual o melhor modelo que representa seu puzzle? Um truque que funciona na maioria das vezes é introduzir variáveis binárias que codificam as informações do seu puzzle.
Por exemplo, a letra S vai ser associada a um dos dígitos de 0 a 9, mas ainda não sabemos qual. Vamos então introduzir dez variáveis binárias: bS0, bS1, .., bS9. Cada uma deles pode assumir o valor 0 ou 1. Por exemplo, se na solução final descobrirmos que S=9, então teremos bS9=1, e as outras nove variáveis são zero.
Mas sabemos que a letra S precisa estar associada a um dígito, e não mais que um. Isso pode ser expresso como a nossa primeira equação:

Confira: para a equação ficar correta, se uma das variáveis for 1, então todas as outras precisam ser 0. (Os mais atentos podem reclamar que eu usei uma equação ao invés de uma inequação, mas não tem problema; toda equação da forma A=k pode ser escrita como duas inequações encadeadas: k ≤ A ≤ k).Criptoaritmética com MIP
O problema então deixa de ser programação e passa a ser modelagem. Qual o melhor modelo que representa seu puzzle? Um truque que funciona na maioria das vezes é introduzir variáveis binárias que codificam as informações do seu puzzle.
Por exemplo, a letra S vai ser associada a um dos dígitos de 0 a 9, mas ainda não sabemos qual. Vamos então introduzir dez variáveis binárias: bS0, bS1, .., bS9. Cada uma deles pode assumir o valor 0 ou 1. Por exemplo, se na solução final descobrirmos que S=9, então teremos bS9=1, e as outras nove variáveis são zero.
Mas sabemos que a letra S precisa estar associada a um dígito, e não mais que um. Isso pode ser expresso como a nossa primeira equação:
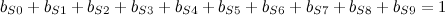
Repetindo uma equação dessas para cada letra, nós garantimos que a cada letra corresponde um dígito. Mas isso não é suficiente, você também precisa garantir o oposto: a cada dígito precisa corresponder uma letra. Sem essa condição adicional, você poderia ter uma solução do tipo S=9 e E=9 (mas não podemos ter o mesmo dígito em duas letras distintas).
A solução é parecida com a anterior. Para o dígito 9, por exemplo, teremos:
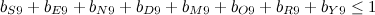
Note que temos apenas oito letras distintas para dez dígitos, então pelo menos dois dígitos vão sobrar. Como não temos como garantir qual dígito será utilizado, usamos uma inequação ao invés de uma equação.
Outra regra que precisa ser modelada é que nenhum número pode começar com zero. Isso é o mesmo que dizer que as letras S e M não podem ser zero. Mais duas equações resolvem isso:
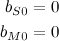
Agora falta só modelar a soma em si. Antes de começar, vale notar que o problema tem quatro variáveis binárias escondidas que você precisa levar em conta: os carrys de cada coluna.
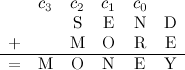
Agora basta escrever uma equação por coluna. Para a coluna mais à direita, por exemplo, teríamos algo do tipo D+E=Y+10c0 em decimal. Usando as nossas variáveis binárias, a equação completa fica:
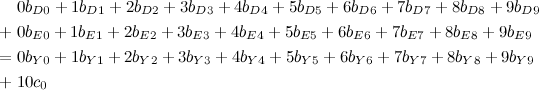
Parece assustador, mas é só uma equação linear simples. Fazendo mais uma dessas para cada coluna do nosso puzzle, o modelo está quase completo: falta só uma função objetivo. Se vamos usar MIP, precisamos minimizar alguma coisa. Mas o que minimizar? Nosso modelo já está completo sem a necessidade de minimizar nada, então podemos fornecer uma função constante para ele minimizar. Na linguagem da área, nós estamos buscando feasibility, e não optimality.
Com todas as inequações prontas, podemos rodar o modelo no EasySCIP. O código completo está no github, e, após rodá-lo em meu computador, tive a resposta em 0.116s, o que é bastante respeitável! Mas ainda dá para melhorar :)
Criptoaritmética com MIP, segundo modelo
Eu sei que gostar de resolver criptoaritmética parece coisa da maluco, mas eu não sou o único maluco nesse mundo, tem o Knuth também! No volume 4A do Art of Computer Programming, ele dá uma dica muito boa para resolver criptogramas: a análise das assinaturas. Vamos isolar a letra E no puzzle original, trocando os lugares onde ela aparece por 1, e onde não aparece por 0:

Após a substituição, nós obtemos a assinatura da letra E, que vale 100+1-10, ou seja, 91. A sacada do Knuth é que, na solução final, a soma das assinaturas precisa necessariamente valer zero:
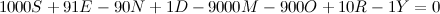
Usando variáveis inteiras ao invés de variáveis binárias, poderíamos colocar essa equação diretamente no modelo, e aí não precisaríamos das equações de cada coluna! Mas podemos fazer ainda melhor: o MIP sempre quer uma função para minimizar, então podemos mandar ele minimizar a soma das assinaturas. Assim, os métodos de branch and bound implementados pelo SCIP podem jogar fora mais nós da árvore durante o processamento, o que acelera a busca.
O único problema é ele resolver minimizar tanto a soma das assinaturas, que ela acabe ficando negativa. Para evitar isso, é só adicionar essa restrição manualmente. Por exemplo, ele pode minimizar a variável X, onde X satisfaz:
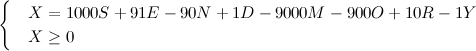
Ainda precisamos adicionar as regras de que a cada letra corresponde um único dígito e vice-versa. Vamos manter as variáveis binárias do modelo anterior, e ensinar o modelo a converter entre variáveis binárias e variáveis inteiras. Por exemplo, a letra D ficaria:
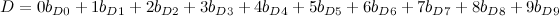
Com isso o modelo está completo. O código está no github, e rodando no EasySCIP, ele chega no mesmo resultado que o modelo anterior, porém usando apenas 0.052s, quase metade do tempo!
Conclusão
Quando eu devo usar MIP ao invés de outros métodos, como backtracking? O backtracking vai criar uma divisão na árvore de busca cada vez que definir o valor de uma variável, mas o MIP roda uma iteração de programação linear em cada nó, o que potencialmente pode definir várias variáveis ao mesmo tempo. A minha experiência é que o MIP ganha sempre que você conseguir criar um modelo que permita essa otimização global.
Como comparação, lembre que a força bruta examinava 1073741824 nós, e a análise de permutações visitava 1814400 nós. Olhando no log do EasySCIP, eu vejo que o primeiro modelo com variáveis binárias visitou apenas 9 nós, e o segundo modelo com assinaturas resolveu tudo em um único nó! A programação linear achou a solução inteira sem nenhum branch! Pelos números, é bem claro que vale a pena aprender a escrever modelos MIP :)
Nenhum comentário:
Postar um comentário