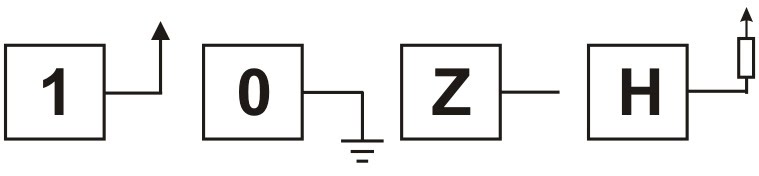Já faz quinze anos que eu assino mailing lists, e uma coisa sempre foi constante em todo esse tempo: as flamewars. Aparentemente, listas na internet têm o poder de enfurecer os participantes e transformá-los em monstros incontroláveis. Ironicamente, essas brigas pela internet são tão previsíveis, que podemos até extrair padrões delas, como a Lei de Godwin.
Dia desses eu fiz uma observação sobre a natureza dessas brigas que os meus amigos apelidaram de Lei de Ricbit. A premissa é simples: as flamewars acontecem em qualquer lista de discussão, mesmo em listas sobre matemática e computação, onde supostamente os leitores são agentes racionais. Como isso pode ocorrer? Será que uma briga poderia acontecer mesmo se o Spock e o Data se encontrassem no Google Wave?
Data: Fiz uma medição surpreendente! Usando os sensores da Enterprise, eu medi os ângulos entre três estrelas distantes, e o resultado é que a soma dos ângulos do triângulo formado pelas estrelas não dá 180 graus!
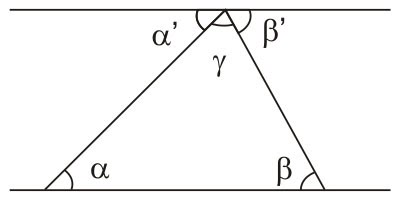
Spock: Fascinante, mas temo que você tenha cometido um erro. Obviamente a soma dos ângulos de um triângulo é sempre 180 graus. Usando a lógica, eu posso provar que isso é sempre é verdade. Basta considerar uma reta paralela à base do triângulo:
Como você pode ver, os ângulos α e α' são alternos internos, e portanto iguais. O mesmo acontece com β e β', logo, a soma dos três ângulos é um ângulo raso.
Data: Como você sabe, andróides não cometem erros de medida. Os ângulos não somaram 180 graus por culpa da teoria da relatividade geral. Objetos tão massivos quanto as estrelas em questão deformam o espaço, o que explica a minha medida. Eu esperava mais dos vulcanos, certamente não se pode questionar os dados experimentais.
Spock: Eu não estava questionando a medida, estava questionando a conclusão. O que você mediu não era um triângulo de verdade, mas sim um outro tipo de figura geométrica de três vértices. Triângulos precisam necessariamente somar 180 graus: se não somarem, não são triângulos. Eu esperava mais dos andróides, certamente não se pode questionar a lógica.
Ricbit: Vocês dois vão ficar discutindo pra sempre, sem concluir nada, e eu vou mostrar o porquê. Muita gente acha que somente a lógica pode levar à verdade, mas isso não é inteiramente correto. A lógica, por si só, pode apenas produzir obviedades. A função real da lógica não é produzir verdades, mas sim transformar verdades. Para usar a lógica na prática, você precisa de verdades básicas, os axiomas, e a partir deles você deriva as verdades mais complexas.
Cada conjunto de axiomas determina um sistema formal. E é por isso que vocês nunca vão concordar, os dois estão partindo de axiomas diferentes! O Spock, ao dizer que alternos internos são iguais, assumiu implicitamente o Postulado das Paralelas do Euclides. Já o Data, ao dizer que o espaço é curvo, assumiu a negação do Postulado das Paralelas, gerando assim uma geometria não-Euclideana. Como os axiomas são diferentes, vocês dois vão discordar sempre, mesmo que usem a lógica perfeitamente.
Spock: Obviamente, eu sabia disso.
Data: Eu também.
Ricbit: Se sabiam, porque continuaram a discussão?
Spock, Data: ...
Ricbit: Olha, que tal esquecer tudo isso? Vamos jogar uma partida de Guitar Hero que é mais divertido.
Spock: Excelente! Eu fico com a guitarra, prefiro os instrumentos de corda.
Data: Onde que o Guitar Hero é instrumento de corda? Não tem corda nenhuma lá, só botão.
Spock: Ora, quando eu clico no botão ele faz som de instrumento de corda.
Data: Mas você não está excitando nenhuma corda, está só apertando um botão! Não tem como dizer que a guitarra do Guitar Hero é um instrumento de corda só porque ela produz som de corda.
Spock: Se for assim, então o piano também não é um instrumento de corda, afinal, você aciona teclas, e não cordas.
Ricbit: (facepalm)
Uma mesma proposição P pode ser verdadeira ou falsa, dependendo do sistema de axiomas que você adota. Mas como decidir qual sistema formal é o correto? A resposta é que você não decide qual é o correto, você escolhe qual é o correto. O único requisito de um sistema formal é que ele seja internamente consistente, fora isso, você escolhe o que for mais útil na ocasião.
O que vale para sistemas formais também funciona informalmente, mas ao invés de axiomas você tem definições. Qual a definição correta de "instrumento de corda"? É o que produz som de corda, ou é aquele onde você excita uma corda diretamente? Novamente, não existe um correto: você escolhe um deles e arca com as conseqüências da sua definição (se você achar que Guitar Hero não é instrumento de corda, então o piano também não vai ser).
Dito isso, agora já podemos enunciar a Lei de Ricbit, em sua forma original:
Lei de Ricbit: Se dois interlocutores discordam de uma definição, então eles vão discutir pra sempre, sem nunca concordar.
E como usar a Lei de Ricbit na prática? Fique de olho em definições conflitantes, que usualmente são implícitas. Por exemplo, um sinal claro de definição conflitante é a expressão "de verdade". FPGA não é hardware livre de verdade, como o Arduino. Java não é orientada a objeto de verdade, como Smalltalk. Quando a pessoa usa "de verdade", está te dizendo que a definição dele é diferente da sua, e aí é inútil prosseguir. E qual definição é a certa, a sua ou a dele? Tanto faz: desde que você seja consistente, pode adotar qualquer uma como verdadeira.
Existem algumas imagens que são icônicas. São tão conhecidas, que só com uma descrição simples você já sabe de qual imagem eu estou falando. O rosto do Che Guevara, a Marilyn com a saia levantada, o chinesinho parando os tanques: todos conhecem essas imagens.
Há quem diga que a imagem da Lena ficou tão famosa entre os cientistas por ser uma imagem complexa o suficiente pra testar qualquer algoritmo: ela tem freqüências baixas e altas, texturas complexas, faixa dinâmica larga. A minha teoria é mais prosaica: se você vai ter que ficar olhando pra mesma imagem por meses, uma mulher bonita é melhor que um babuíno de nariz vermelho :)
Mas a imagem da Lena tem um segredo que nem todos conhecem. Quando eu descobri a origem da imagem, fiquei doido pra conseguir uma cópia original da fonte de onde essa imagem saiu. E depois de anos procurando, finalmente consegui:
Clique na imagem pra ver a versão completa, NSFW
Sim, a imagem usada por cientistas do mundo todo, na verdade, é um centerfold da Playboy!
Essa edição é a Playboy americana de novembro de 1972. Eu corajosamente a comprei no ebay, mesmo com os avisos que diziam "warning: pages may be sticky". Foi um ótimo negócio, o vendedor me vendeu uma Playboy usada, e eu comprei um pedaço da história da computação :)
A origem da imagem é curiosa. Conta-se que o pesquisador tinha um paper pra entregar no dia seguinte, e precisava de uma imagem com urgência. Ele acabou digitalizando a primeira revista que achou em sua mesa, a edição da Playboy com a Lena, que, curiosamente, também foi a edição mais vendida da história da revista. Ele não contou pra ninguém a origem da imagem, e por anos muitos usaram a imagem sem conhecer a história dela.
Isso acabou gerando um problema quando a Playboy descobriu que uma das suas imagens estava sendo copiada indiscriminadamente por aí. Inicialmente, ela tentou impedir o uso da imagem, mas depois acabou descobrindo que era boa propaganda, e hoje em dia a diretoria da revista faz vista grossa para o assunto.
Por outro lado, como a imagem ainda tem copyright, nunca se sabe se um dia a diretoria não vai mudar de idéia e vetar novamente o uso. Se você precisa de uma nova imagem de teste, agora tem uma nova solução! A minha esposa (ilustradora, modelo e atriz), fez um remake da imagem da Lena, e disponibilizou com a licença Creative Commons Attribution-Share Alike. E se você usar a imagem em algum paper, eu ainda posso fazer um peer review na faixa pra você.
iLena
Obviamente, a versão original dessa imagem só eu tenho :)
Dia desses, um amigo me perguntou se eu conseguiria fazer uma lista com os meus cinco emuladores prediletos. Esse é o tipo de pergunta que, normalmente, é difícil de responder. Eu já escrevi um monte de emuladores, já conversei com inúmeros autores, e era de se esperar que fosse muito díficil criar uma lista assim. Afinal, sempre que você faz um top five, precisa deixar muita coisa bacana de fora, especialmente se você conhece bastante o assunto.
Porém, surpreendentemente, fazer a lista foi fácil! Tem cinco emuladores que se destacam, pela enorme influência que tiveram em tudo que se seguiu. Em ordem cronológica reversa:
VMware (2001)
No fim da década de 90, quando se falava em emuladores, imediamente as pessoas pensavam em videogames. O VMware trouxe de volta os emuladores ao mundo corporativo. As aplicações são inúmeras: desenvolvedores, por exemplo, podem programar no Linux, e testar a aplicação num Windows emulado. Em datacenters o impacto é ainda maior. Usando a versão ESX, os administradores de datacenter podem usar uma mesma imagem em todos os servidores, mesmo que eles sejam heterogêneos; e dá até pra trocar uma imagem de um servidor para outro enquanto ela está rodando, com downtime mínimo.
O truque do VMware pra conseguir desempenho é que a virtualização dele tenta evitar a emulação tanto quanto possível. Em algumas situações, como código rodando em user space, o VMware roda o código diretamente na CPU. Ele só usa emulação nos trechos críticos, como código rodando em kernel space, ou código acessando periféricos que foram virtualizados.
bleem (1999)
Se o VMware mudou a percepção que o povo da época tinha dos emuladores, o bleem foi igualmente importante, ao mudar a percepção do underground para o mainstream. Até então, emuladores de videogame eram um produto de nicho, conhecidos só por alguns poucos viciados em internet. O bleem, que na época era o melhor emulador de Playstation, levou os emuladores para as lojas. Hoje nós temos um mercado construído em cima da emulação de jogos, como prova o sucesso do Virtual Console no Wii, e quem começou esse mercado foi o bleem.
Mas pra mim o bleem tem um significado mais especial. Naquela época em que fazíamos emuladores, ninguém tinha muita certeza se nós estávamos dentro da legalidade ou não. Quando o bleem começou a bombar, a Sony processou os criadores do bleem, e depois de uma ferrenha briga judicial, o bleem saiu vitorioso. Eu passei a dormir mais tranquilo depois disso :)
O emulador de 8080 do Paul Allen (1975)
O Bill Gates sempre foi bom de blefe. Quando ele descobriu que a MITS estava fazendo o Altair 8800, ele entrou em contato com os fabricantes para oferecer um interpretador BASIC. Os fabricantes se empolgaram e marcaram uma reunião pra fazer uma demonstração. O problema é que não havia demo, foi tudo um blefe do Bill! Com a reunião marcada, ele e o sócio Paul Allen tiveram que correr pra preparar um demo a tempo. O blefe era tão vazio, que eles nem tinham um Altair pra poder programar.
Como criar um interpretador para o Altair, sem ter um Altair? A solução que eles encontraram foi a emulação. Enquanto o Bill Gates escrevia o interpretador, o Paul Allen escreveu um emulador de 8080, a CPU usada no Altair. Como eles também não tinham computador pra rodar o emulador, testavam o software deles no PDP-10 da Harvard, a faculdade onde estudavam. No final, eles acabaram a tempo, e criaram a Microsoft para vender aquele interpretador. Poucos emuladores podem ser tão influentes assim :)
IBM System/360 (1964)
Tem muitas coisas que são naturais para nós, mas que eram o ápice da inovação no passado. Upgrades, por exemplo. Hoje em dia, se o seu programa está rodando muito lento, você pode comprar um computador mais novo e o programa rodará mais rápido. Mas antigamente isso não era verdade: se você comprasse um computador novo, iria precisar de um software novo também. Não existia portabilidade.
A IBM mudou isso com o IBM System/360, uma família de computadores projetada com a compatibilidade em mente. Você poderia comprar um System/360 pequeno, e se precisasse de mais processamento, era só comprar um modelo maior, rodando o mesmo software. E se não bastasse isso, a IBM ainda garantia compatibilidade com modelos anteriores ao System/360! O segredo, é claro, era emulação: a IBM criou emuladores de seus sistemas mais antigos e populares. Não por acaso, o System/360 foi o computador mais vendido de sua época.
A máquina universal de Turing (1936)
No começo do século XX, os matemáticos estavam procurando a solução do Entscheidungsproblem: existe um processo capaz de decidir se uma expressão matemática é verdadeira ou não? Na época ainda não existia o conceito de algoritmo, o Turing teve que partir do zero. Ele construiu um modelo computacional, a máquina de Turing, e a usou pra chegar na decepcionante conclusão de que o tal algoritmo de decisão não existe. Por outro lado, ele concluiu que, para todos os algoritmos que existem, também existe uma máquina de Turing capaz de executá-lo (essa é a tese de Church-Turing).
Mas o Turing foi além. Baseado no trabalho do Gödel, ele concebeu uma máquina de Turing mais poderosa, que era capaz de rodar qualquer algoritmo que outra máquina de Turing conseguisse. O truque, como vocês devem ter deduzido, é usar emulação. As máquinas universais de Turing não apenas são o modelo matemático que permite a existência de emuladores, como também de toda a computação.
No último post, nós vimos como funciona uma FPGA. Agora é hora de aprender a usá-la na prática, e o melhor jeito é fazendo um pequeno projetinho. Como exemplo de projetinho, eu pensei que poderíamos construir um Cilônio a partir do zero:
Para começar a desenvolver para FPGAs, a primeira coisa de que você precisa é, obviamente, uma FPGA. Se você for o tipo de ninja que consegue soldar SMD na mão, pode fazer sua própria placa de desenvolvimento. Eu, como sou inepto com ferro de solda, optei por comprar um kit de desenvolvimento na Digilent. O kit que escolhi foi o S3EBOARD, que tem o menor custo/benefício:
Essa placa custa 150 dólares. Se você comprar do Brasil, somando o frete e impostos, pode ficar meio salgado, mas no final vale a pena. Uma FPGA sozinha não serve pra muita coisa, a coisa só fica divertida quando você a usa pra controlar algum dispositivo. E essa placa da Digilent tem todos os dispositivos que você precisa! Ela tem RAM, conector VGA, PS/2 pra teclado, serial pra mouse, conector Ethernet, DACs pra fazer saída de som, enfim, com ela você pode fazer um computador completo.
Em especial, no cantinho da placa tem uma série de 8 LEDs. Com isso, já podemos escolher por onde vamos começar a fazer o nosso Cilônio. Já que temos LEDs enfileirados, vamos começar pelo visor!
Já temos uma placa com a FPGA, precisamos agora de um compilador para programá-la. Eu uso o Xilinx ISE Webpack, que é free (as in beer), e disponível para Windows e Linux. Compiladores de FPGA são análogos aos compiladores de software, até mesmo na idéia de compilar em etapas. Um compilador típico de C tem estágios de pré-processamento, compilação, otimização e linking. Um compilador para FPGA possui as seguintes etapas:
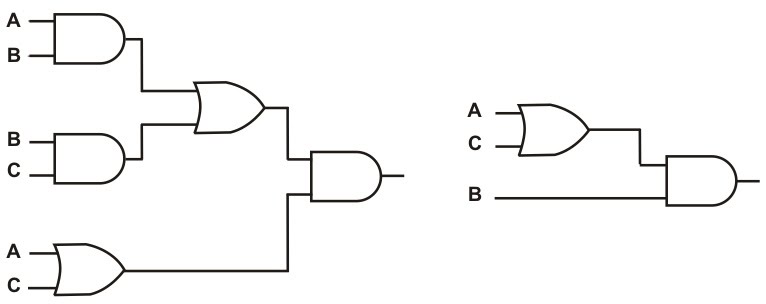
Síntese: Tudo começa com a sua descrição do projeto, feita em alguma linguagem de descrição de hardware. Para começar o processo, o compilador traduz essa linguagem para uma representação RTL, que é basicamente um sistema de equações booleanas. Essas equações são então simplificadas, de modo a eliminar redundâncias e deixar o circuito final mais rápido.
Circuito original, e circuito após otimização
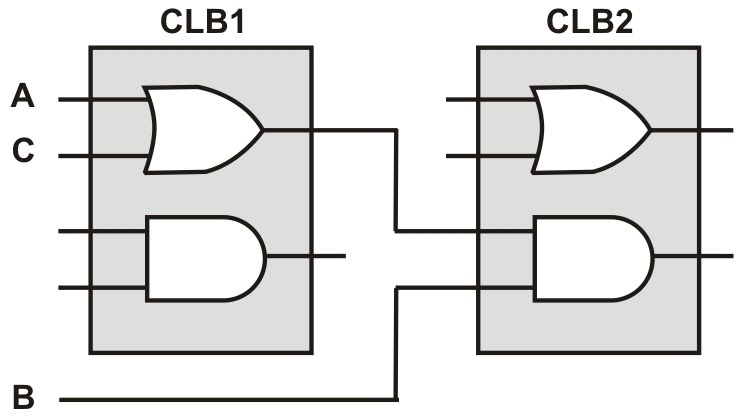
Mapeamento tecnológico: Mesmo que o otimizador tenha chegado nas equações booleanas mínimas, elas ainda não podem ser usadas na FPGA. Nós sabemos que a FPGA é formada de blocos lógicos (os CLBs), então precisamos de um processo para mapear as equações nos CLBs. Note que a etapa de síntese não depende da arquitetura, mas na etapa de map o compilador precisa saber o modelo exato da FPGA sendo usada, já que cada FPGA tem um tipo de CLB diferente.
Mapeamento tecnológico, cada CLB tem um AND e um OR
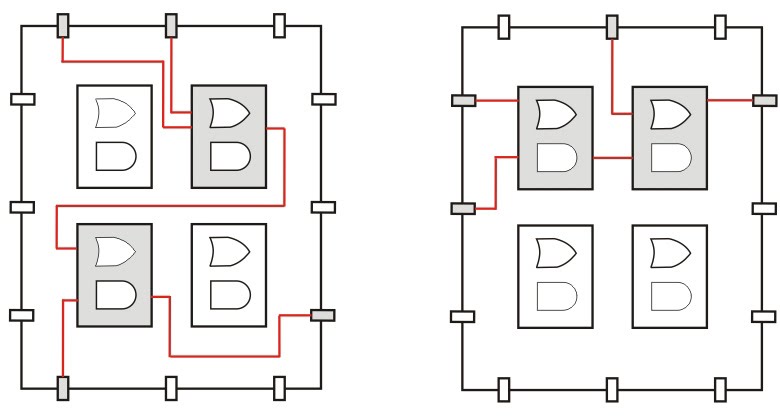
Place and Route: Depois de feito o mapeamento tecnológico, o compilador sabe quantas CLBs ele precisa, e como preencher cada uma delas. Mas ele ainda não escolheu quais CLBs serão usadas. Apesar das CLBs serem todas iguais, se você utilizar CLBs muito distantes entre si, o tempo que o sinal leva de uma a outra pode influir na velocidade do seu circuito. Na etapa de place and route, o compilador escolhe a melhor disposição de CLBs para o seu design.
Antes e depois do place and route
Geração da bitstream: Por fim, o compilador gera uma bitstream que é usada pra programar a FPGA, usualmente através de uma interface JTAG. A partir desse ponto, sua FPGA está programada e pronta pra rodar :)
Agora precisamos escolher a linguagem que vamos usar. O Xilinx Webpack suporta VHDL e Verilog. Escolher uma das duas é como escolher vi ou emacs, existem fãs dos dois lados, mas na prática são quase equivalentes. Em geral, para quem está começando, eu recomendo não pensar muito e escolher aquela que seus amigos usam (assim você tem pra quem perguntar quando tiver dúvidas). Eu acabei escolhendo usar VHDL.
A origem da linguagem VHDL é curiosa. O departamento de defesa americano fazia muitos contratos de fabricação de chips, mas a documentação que vinha de cada fabricante era diferente. Eles então bolaram um padrão, o VHDL, que no começo era simplesmente um jeito de documentar circuitos. Em um certo ponto, notaram que a documentação era precisa o suficiente pra permitir simulação, e da simulação partiram para a síntese.
Mas vamos ao nosso projeto. A primeira parte de um design em VHDL, assim como em faríamos em software, são os imports:
O motivo de incluir essas bibliotecas é que sem elas não podemos usar bits em hardware. Bits em software são simples, eles podem ser 0 ou 1. Já em hardware, temos muito mais opções. Além do "0" (pino ligado no GND) e do "1" (pino ligado no Vcc), também temos o "Z" (pino não conectado), "H" (pino ligado no Vcc através de um pull-up), e assim por diante. Em VHDL, bits de hardware são chamados de std_logic.
Alguns estados do std_logic
Em seguida nós precisamos definir a entidade que vamos fazer. Uma entidade em VHDL é como uma interface em Java, ela define como seu código interage com o mundo. Em hardware, isso é equivalente a definir quem serão os pinos de entrada e saída do seu design. No nosso projeto, nós precisamos de duas entradas: um clock e um botão de liga-desliga; e oito saídas: uma para cada LED.
Agora vamos definir a implementação da interface, que em VHDL é o behaviour. No nosso projeto, vamos usar um clock de 50MHz, rápido demais para fazer a animação dos LEDs. Precisamos então dividir essa freqüência, pra isso vamos usar um contador que reseta a cada 5 milhões de ciclos. Cada vez que o contador resetar, nós incrementamos um estado da nossa máquina de estados, e, por fim, vamos associar cada estado a uma combinação de LEDs acesos e apagados.
Se fosse software, precisaríamos de três variáveis pra implementar esse algoritmo. Em hardware, não usamos variáveis, mas sim registradores. Uma parte curiosa do VHDL é que você não define os registradores diretamente; ao invés disso, você define os sinais e ele infere quais registradores você precisa. Como você deve imaginar, num projeto grande isso é fonte de inúmeros bugs! Felizmente, nesse projetinho não vamos ter esse problema.
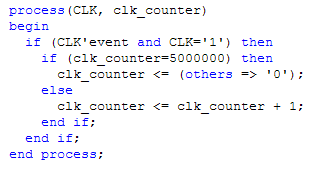
Note que ao especificar um registrador, você precisa falar o tamanho dele. Nosso contador de clocks, por exemplo, vai de 0 a 5 milhões, e portanto cabe num registro de 23 bits. Vamos aproveitar e implementar esse contador. A diferença mais importante de hardware e software é que no hardware você tem paralelismo real, não é time-sharing e nem tem limite no número de cores. Em VHDL, cada unidade que roda em paralelo é um processo:
Na primeira linha de cada processo você define quem são as entradas (nesse caso, o clock e o valor anterior do contador). O primeiro if checa se aconteceu uma mudança no clock que o levou para o estado 1 (ou seja, o código dentro do if só roda em uma borda de subida). O resto é como em software, se chegar a 5M, volte a zero, senão incremente.
O processo seguinte faz o mesmo com o contador do estado atual:
O contador de estado incrementa na borda de subida, mas só quando o contador de clock é zero. Além disso, nós também zeramos o estado quando a chave SW0 está desligada (implementando assim um botão que liga e desliga).
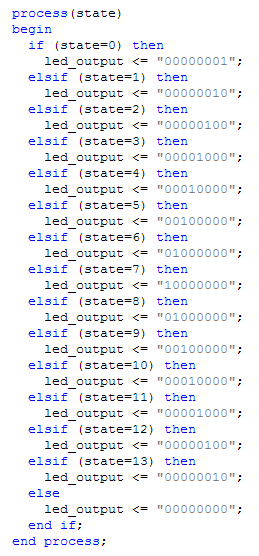
Agora precisamos associar cada estado a uma combinação de LEDs (o que, em hardware, chamamos de demultiplexação):
Note que além de definir todos os estados possível, ainda temos um else extra. Precisamos sempre lembrar que, em hardware, bits não são apenas 0 ou 1! Se o estado cair em algum dos outros valores, como Z ou H, precisamos do else extra para cuidar dele.
Por fim, precisamos ligar o demultiplexador nos pinos de saída. Ligações simples de sinais nem precisam de um processo:
Agora o VHDL está pronto, mas ainda falta um detalhe para acabar o projeto. O VHDL cuida de tudo que vai acontecer dentro da FPGA, mas ainda precisamos cuidar do que está fora dela. Pra isso, precisamos de um constraint file, que vai indicar em quais pinos da FPGA estão ligados nossos periféricos (os LEDs, o clock, etc). Esses valores nós pegamos diretamente do manual do kit da Digilent. Nossos arquivos ficaram assim, então: